
Use Truelty to auto-generate the required code within your Snowflake instance.
No need to ship your data to a 3rd party for processing data duplication! Since Truelty’s code as a service only has access to operational metadata and no actual data access, your data is safely stored in Snowflake without risk of being sold to 3rd parties. Additionally, Truelty auto generates the identity resolution code on an Admin-only view of query histories to keep the processing of your regular job history free from the noise of parallel processes.
Decoupled licensing from your contact counts allows you to affordably process customer records without skyrocketing costs. This also means you can load as many data sources into Snowflake as you like, and Truelty’s code as a service can have Snowflake process them. This means the only variable costs are your negotiated credit usage rates.
Truelty has created a code generator that produces identity resolution logic we call Deep Chaining to pair and match records.
This method leverages the scalability of Asynchronous Queries in Snowflake to parallel process a sequence of pairings. Truelty densely packs the compute of these query chain links into Snowflake to eek every last drop of compute power allocated.
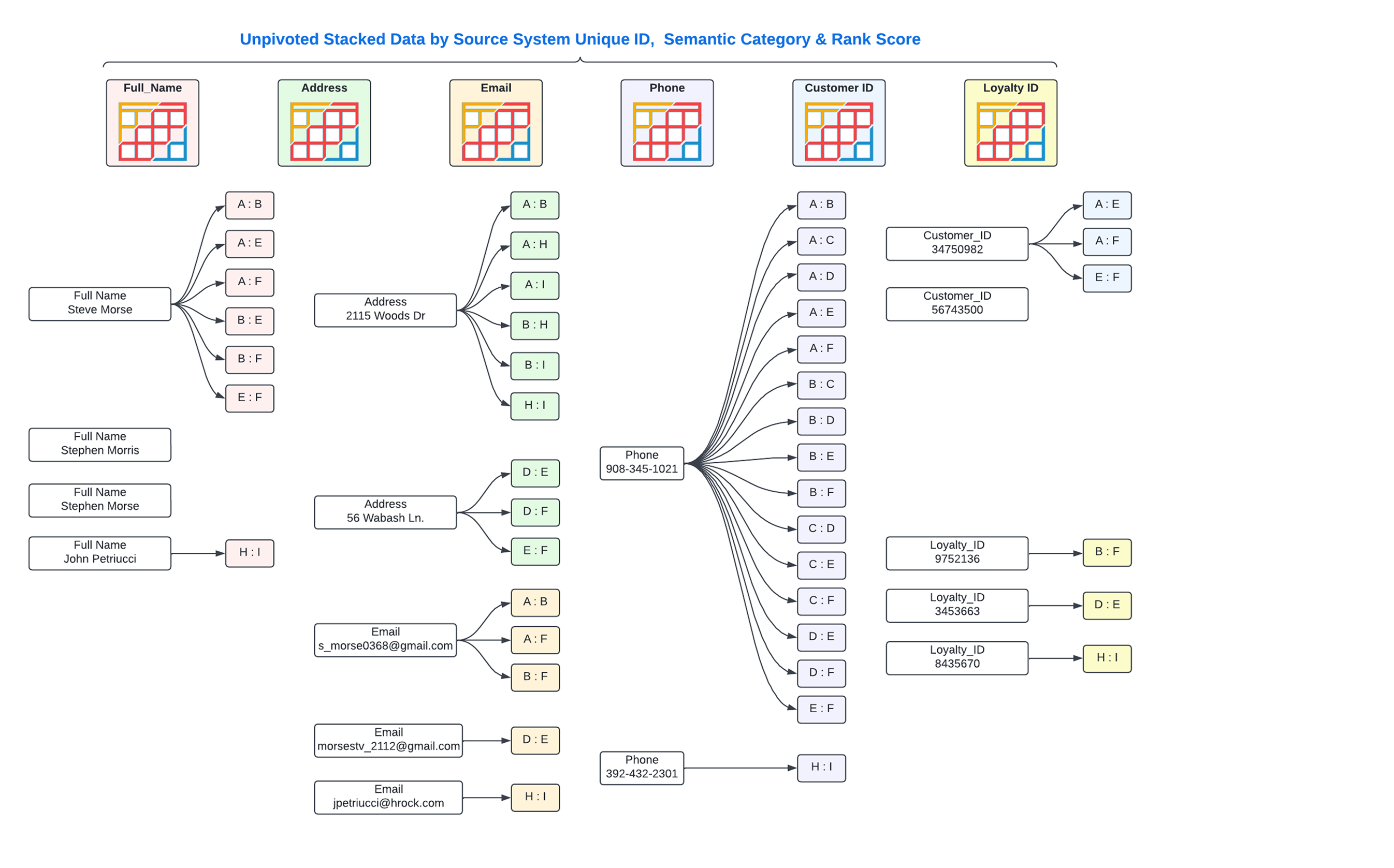
Truelty creates its own tables and processing location in your Snowflake instance so there is no disruption to your existing data sets. In this new space, Truelty stipes the tables into their respective semantic categories and creates a unique ID for each record which provides a “ip address” of the record. Truelty densely packs Snowflake Micro Partitions into highly efficient representation of that semantic category.
From there, Truelty leverages hyper packed micro-partitions to start a deep chain comparison algorithm, all processed in Snowflake, published by the Truelty code generators. These generators produce the highly optimized asynchronous set of Snowflake queries that build out the deep chain to ultimately create unique cluster IDs for duplicate records it finds in your data.

This chain’s newly created cluster IDs are paired with the unique record ID (“IP Addresses”) of the source records. So in the end Truelty produces a table with two critical columns. One with the unique record ID and the cluster ID. Any unique record ID’s that have the same Cluster IDs represent the same customer. This table is easily referenced in downstream applications and customer queries.
Snowflake Performance
At the outset, Truelty came at this matching problem with an awareness of scaling to maximize processing in Snowflake. The query generators therefore are highly adapted at every step in the deep chaining process to densely pack and correctly size the Snowflake warehouses. So it is not uncommon for Truelty to optimize parallelism with 10 XSmall warehouses.
Because Truelty pushes the envelope on auto configuration of Warehouses, and generates an extensive history of jobs, Truelty keeps these warehouses separate from the regular inventory of warehouses so only Administrators can see the active job history of the Truelty code generators.
So whether you have billions of records or millions, the code generators will tune the deep chain for highest efficiency.
Consequently, when Snowflake compute is being used, you can rest assured that it is being processed at maximum efficiency, maximum scale, and minimum cost.
Get started with Truelty and tell us a little about your current Identity Resolution needs
What is required to get started?
- 1
Snowflake instance
Running Enterprise or higher editions - 2
Load data
Data from enterprise applications, 3rd party data, cloud applications etc loaded into Snowflake - 3
Run the set-up
Python application and Snowflake permissions. All pre-scripted, takes about an hour. This creates a secure area for Truelty to process and avoids any conflicts with existing databases of schemas - 4
Land zone or View
Land the data in the Truelty landing zone or point Truelty to a view. This is in your Snowflake instance. Load new or changed data at any interval you choose - 5
Audit auto-mapped columns in the Control plane
Truelty runs native Snowflake profiling on the columns to match it to Truelty’s Semantic Categories. Here you can audit the output to validate any required changes and flag columns in meaningful ways - 6
Schedule the resolution process to run
The control plane creates a table in Snowflake which the Truelty python application uses to auto-execute the ID resolution code